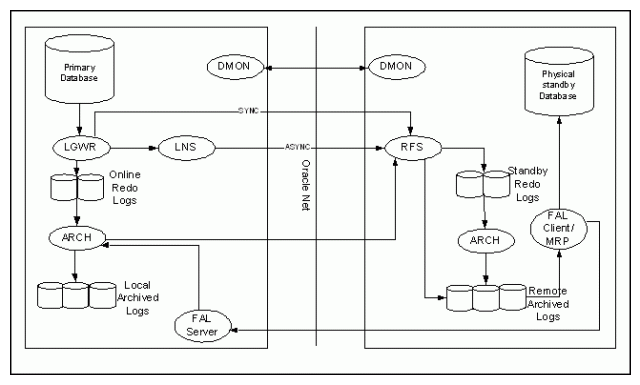
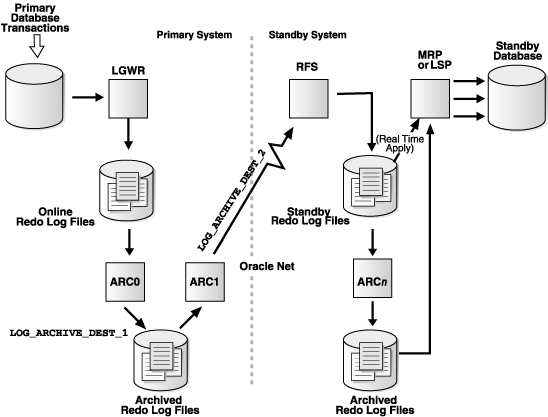
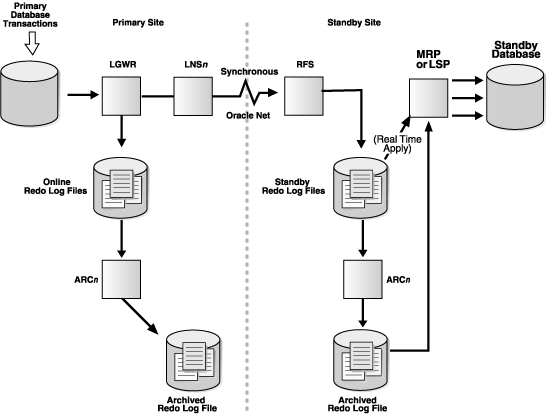
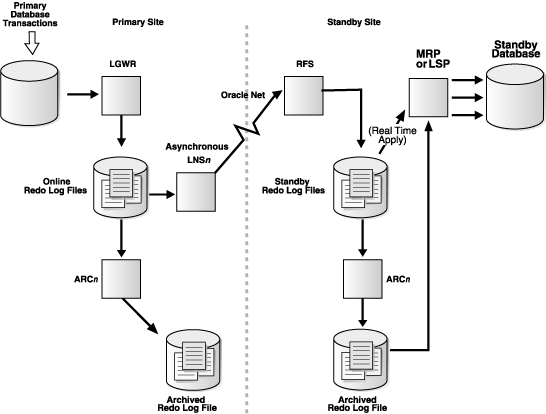
In this post I have demonstrated Step by Step approach to create an Oracle 12c Data Guard Active Standby Database.
Environment Setup details
- Primary database up and running on 4 node RAC
- Data files, OCR and voting Disks(in separate DG) are in ASM storage.
- Binaries are in files system .
- DB Password files and init<sid>.ora files are in $ORACLE_HOME/dbs
- Installed and Configured Grid Infra on Standby machines, 4 Node RAC.
- OCR and voting Disks(in separate DG) are in ASM storage.
- Created required Disk group on Standby site for data files.
- RDBMS software installed in standby machines.
- Ensured Network connectivity between PRIMARY and STANDBY server (TCP/IP – Port 1521 & 1525).
Environment details – Primary Databases
| OS Version: Linux 6.2 |
| Oracle Version: 12.1.0.2 |
| Host Server: LABPRD1, LABPRD2, LABPRD3, LABPRD4 |
| Primary DB : PRASPRD Instances : PRASPRD1,PRASPRD2,PRASPRD3,PRASPRD4 |
| Storage System: ASM for Data Storage and Filesystem for Binaries |
| Grid Home(Binaries): /prasprd/gridinfra/grid1 |
| RDBMS Home(Binaries) :/prasprd/db/db1 |
| Disk Groups: CRS1(High Redundancy, For OCR and Voting Disk), LABDATA2(Data files, Red logs and Control files) |
Environment details – Standby Databases
| OS Version: Linux 6.2 |
| Oracle Version: 12.1.0.2 |
| Host Server : LABSBY1, LABSBY2, LABSBY3, LABSBY4 |
| Primary DB : PRASSBY Instances : PRASPRD1,PRASPRD2,PRASPRD3,PRASPRD4 |
| Storage System: ASM for Data Storage and Filesystem for Binaries |
| Grid Home(Binaries): /prasprd/gridinfra/grid1 |
| RDBMS Home(Binaries) :/prasprd/db/db1 |
| Disk Groups: CRS1(High Redundancy, For OCR and Voting Disk), LABDATA3(Data files, Red logs and Control files) |
Procedure
- Enable force logging in PRIMARY.
- Create SRL (standby redo logs) in PRIMARY.
- Copy init and password file from primary to STANDBY.
- Create directory structure in STANDBY.
- Make Standby parameter changes in the parameter file of PRIMARY.
- Make Standby parameter changes in the parameter file of STANDBY.
- Add an entry in the oratab file
- Establish the connectivity between PRIMARY and STANDBY.
- Start the STANDBY instance
- Use RMAN duplicate to create standby database from PRIMARY database.
- Start the MRP process in STANDBY.
- Verify whether the log are shipped and applied properly @the STANDBY.
- Start other standby RAC nodes.
- Verify Pluggable database’s status.
Step by Step Active Standby Build
1. Enable force logging on PRIMARY
SQL> alter database force logging;
2. Configure Standby Redo Log on PRIMARY
a. Check the log files and sizes.
SQL>SELECT GROUP#, BYTES FROM V$LOG;
b. Create SRL
SQL> ALTER DATABASE ADD STANDBY LOGFILE THREAD <TN> GROUP <GN> (‘/path/<File Name>’, ‘/path/<File Name>’ ) SIZE <S> ;
NOTE: SIZE OF STANDBY LOG FILE SHOULD BE SAME AS ONLINE LOG FILE
c. Verify the standby redo log file groups were created .Verify this in standby after standby build.
SQL> SELECT GROUP#, THREAD#, SEQUENCE#, ARCHIVED, STATUS FROM V$STANDBY_LOG;
(Primary)
| GROUP# |
THREAD# |
SEQUENCE# |
ARC |
STATUS |
| 9 |
1 |
0 |
YES |
UNASSIGNED |
| 10 |
1 |
0 |
YES |
UNASSIGNED |
| 11 |
2 |
0 |
YES |
UNASSIGNED |
| 12 |
2 |
0 |
YES |
UNASSIGNED |
| 13 |
3 |
0 |
YES |
UNASSIGNED |
| 14 |
3 |
0 |
YES |
UNASSIGNED |
| 15 |
4 |
0 |
YES |
UNASSIGNED |
| 16 |
4 |
0 |
YES |
UNASSIGNED |
(Standby – Below table output after the standby is created)
| GROUP# |
THREAD# |
SEQUENCE# |
ARC |
STATUS |
| 9 |
1 |
0 |
YES |
UNASSIGNED |
| 10 |
1 |
509 |
YES |
ACTIVE |
| 11 |
2 |
0 |
YES |
UNASSIGNED |
| 12 |
2 |
298 |
YES |
ACTIVE |
| 13 |
3 |
0 |
YES |
UNASSIGNED |
| 14 |
3 |
500 |
YES |
ACTIVE |
| 15 |
4 |
0 |
YES |
UNASSIGNED |
| 16 |
4 |
287 |
YES |
ACTIVE |
**Here I have 4 nodes having 2 redo groups each node, total 8 groups; created 8 more standby log groups 2 per node.
3. Copy init and password file from primary to standby
Copy initPRASPRD1.ora to standby database (all 4 Nodes), name of init<sid>.ora needs to be changed depends on instance names
Copy the password file orapwPRASPRD1 from primary to standby database (all 4 nodes), name of init needs to be changed depends on instance names
4. Create directory structure in standby
$ mkdir -p /u01/app/oracle/admin/prasprd/adump (on all 4 node)
5. Make Standby parameter changes in the parameter file of PRIMARY.
Add below entries in the init<sid>.ora.(Make the entry in one Node pfile and copy to other nodes)
$ cat initprasprd1.ora
##########DG Enrty ################
*.log_archive_max_processes='8'
*.db_unique_name=PRASPRD'
*.log_archive_config='dg_config=(PRASSBY,PRASPRD)'
*.log_archive_dest_1='location=+LABDATA2 valid_for=(all_logfiles,all_roles)
*.log_Archive_dest_2='service=PRASSBY_DR async noaffirm reopen=15 valid_for=(all_logfiles,primary_role) db_unique_name=PRASSBY'
*.log_file_name_convert='+LABDATA3','+LABDATA2'
*.db_file_name_convert='+LABDATA3','+LABDATA2'
*.fal_server=PRASSBY_DR;
*.fal_client=PRASPRD;
#############DG Entry ############################
6. Make Standby parameter changes in the parameter file of Standby
Add below entries in the init<sid>.ora.(Make the entry in one Node pfile and copy to other nodes)
$ cat initprasprd1.ora
##########DG Enrty ################
*.log_archive_max_processes='8'
*.db_unique_name='PRASSBY'
*.standby_file_management='AUTO'
*.log_archive_config='dg_config=(PRASPRD,PRASSBY)'
*.log_archive_dest_1='location=+LABDATA3 valid_for=(all_logfiles,all_roles) db_unique_name=PRASSBY'
*.log_Archive_dest_2='service=PRASPRD async noaffirm reopen=15 valid_for=(all_logfiles,primary_role) db_unique_name=PRASPRD'
*.log_file_name_convert='+LABDATA2','+LABDATA3'
*.db_file_name_convert='+LABDATA2','+LABDATA3'
*.fal_server=PRASPRD
*.fal_client=PRASSBY_DR
#############DG Entry ############################
7. Add an entry in the oratab file
PRASPRD1: /prasprd/db/db1: N (Node1)
PRASPRD2: /prasprd/db/db1: N (Node2)
PRASPRD3: /prasprd/db/db1: N (Node3)
PRASPRD4: /prasprd/db/db1: N (Node4)
8. Establish the connectivity between PRIMARY and STANDBY.
On Standby (Add a static entry in the listener.ora for PRASSBY)
LISTENER12C =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST =LABSBY1.me.domain)(PORT = 1525))
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1525))
)
)
SID_LIST_LISTENER12C =
(SID_LIST =
(SID_DESC =
(GLOBAL_DBNAME = PRASSBY)
(ORACLE_HOME = /prasprd/db/db1)
(SID_NAME = PRASPRD1)
)
)
Reload the listener
$ lsnrctl reload listener12c
LSNRCTL for Linux: Version 12.1.0.2.0 - Production on Tue Jan 6 12:11:31 2015
Copyright (c) 1991, 2014, Oracle. All rights reserved.
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST= LABPRD1.me.domain) (PORT=1525)))
The command completed successfully
On Primary (Add a below entry on tnsnames.ora)
PRASSBY_DR =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = LABSBY1.me.domain)(PORT = 1525))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME =PRASSBY)
)
)
PRASPRD =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST =LABPRD1.corporate.domain)(PORT = 1525))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = PRASPRD)
)
)
On Standby(Add a below entry on tnsnames.ora)
PRASSBY_DR =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = LABSBY1.corporate.domain)(PORT = 1525))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME =PRASSBY)
)
)
PRASPRD =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST =LABPRD1.corporate.domain)(PORT = 1525))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = PRASPRD)
)
)
9. Start the STANDBY database instance.
$ . oraenv
ORACLE_SID = [prasprd1] ? prasprd1
The Oracle base has been set to /u01/app/orabase
oradb@PRASSBY1.ME.DOMAIN:/home/oradb ~]sqlplus / as sysdba
SQL*Plus: Release 12.1.0.2.0 Production on Tue Jan 6 12:11:31 2015
Copyright (c) 1982, 2014, Oracle. All rights reserved.
Connected to an idle instance.
SQL> startup nomount;
ORACLE instance started.
Total System Global Area XXXXXXXXX bytes
Fixed Size XXXXXXX bytes
Variable Size XXXXXXXXX bytes
Database Buffers XXXXXXXX bytes
Redo Buffers XXXXXXX bytes
10. Use RMAN duplicate to create standby database on Primary database.
Recovery Manager: Release 12.1.0.2.0 – Production on Tue Jan 6 14:40:12 2015 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved.
RMAN> connect target sys/*****@PRASPRD connected to target database: PRASPRD (DBID=2845711114)
RMAN> connect auxiliary sys/*****@PRASSBY_DR
connected to auxiliary database: PRASPRD (not mounted)
run
{ allocate channel c1 type disk;
allocate channel c2 type disk;
allocate auxiliary channel aux type disk;
duplicate target database for standby from active database;
alter system set log_archive_max_processes=’8′;
alter system set db_unique_name=’PRASSBY’;
alter system standby_file_management=’AUTO’;
alter system set log_archive_config=’dg_config=(PRASPRD,PRASSBY)’;
alter system set log_archive_dest_1=’location=USE_DB_RECOVERY_FILE_DEST valid_for=(all_logfiles,all_roles) db_unique_name=PRASSBY’;
alter system set log_Archive_dest_2=’service=prasprd async noaffirm reopen=15 valid_for=(all_logfiles,primary_role) db_unique_name=PRASPRD’;
log_file_name_convert=’+LABDATA3′,’+LABDATA2′
db_file_name_convert=’+LABDATA3′,’+LABDATA2′ }
11. Start the MRP process on standby database
SQL> startup ;
ORACLE instance started.
Total System Global Area XXXXXXXXX bytes
Fixed Size XXXXXXX bytes
Variable Size XXXXXXXXX bytes
Database Buffers XXXXXXXXX bytes
Redo Buffers XXXXXXX bytes
Database mounted.
Database opened. SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;
Media recovery complete
12. Verify MRP process on standby database
oradb@LABPRD.CORPORATE.DOMAIN:/home/oradb ~]ps -ef | grep mrp
oradb 23678 1 0 Jan05 ? 00:00:05 ora_mrp0_prasprd1
SQL> select process,status,thread#,sequence#,blocks from v$managed_standby where process like ‘%MRP%’;
| PROCESS |
STATUS |
THREAD# |
SEQUENCE# |
BLOCKS |
| MRP0 |
APPLYING_LOG |
1 |
498 |
102400 |
13. Verify whether the log are shipped and applied properly @the standby.
On Primary
SQL> ALTER SYSTEM SWITCH LOGFILE;
SQL > select thread#, max(sequence#) “Last Primary Seq Generated”
From v$archived_log val, v$database vdb
where val.resetlogs_change# = vdb.resetlogs_change#
group by thread# order by 1;
| THREAD# |
LAST PRIMARY SEQ GENERATED |
| 1 |
497 |
| 2 |
283 |
| 3 |
484 |
| 4 |
277 |
On Standby
SELECT ARCH.THREAD# “Thread”, ARCH.SEQUENCE#
“Last Sequence Received”,
APPL.SEQUENCE# “Last Sequence Applied”,
(ARCH.SEQUENCE# – APPL.SEQUENCE#) “Difference”
FROM
(SELECT THREAD# ,SEQUENCE# FROM V$ARCHIVED_LOG
WHERE
(THREAD#,FIRST_TIME )
IN (SELECT THREAD#,MAX(FIRST_TIME)
FROM V$ARCHIVED_LOG GROUP BY THREAD#))
ARCH,(SELECT THREAD# ,SEQUENCE#
FROM V$LOG_HISTORY
WHERE (THREAD#,FIRST_TIME )
IN (SELECT THREAD#,MAX(FIRST_TIME) FROM V$LOG_HISTORY
GROUP BY THREAD#)) APPL
WHERE ARCH.THREAD# = APPL.THREAD# ORDER BY 1;
| THREAD# |
LAST SEQUENCE RECEIVED |
LAST SEQUENCE APPLIED |
DIFFERENCE |
| 1 |
497 |
497 |
0 |
| 2 |
283 |
283 |
0 |
| 3 |
484 |
484 |
0 |
| 4 |
277 |
277 |
0 |
14. Startup other RAC standby node.
SQL> startup open;
15. Check pluggable database and status in PRIMARY and STANDBY.
On Primary
SQL> select name, open_mode from v$pdbs; or show pdbs
| NAME |
OPEN_MODE |
| PDB$SEED |
READ ONLY |
| PDB1 |
MOUNTED |
| PDB2 |
MOUNTED |
On Standby
SQL> select name, open_mode from v$pdbs; or show pdbs
| NAME |
OPEN_MODE |
| PDB$SEED |
READ ONLY |
| PDB1 |
MOUNTED |
| PDB2 |
MOUNTED |
16. Check database ROLE
On Primary
SQL> select NAME, DATABASE_ROLE, SWITCHOVER_STATUS,DB_UNIQUE_NAME,CDB,CON_ID from v$database;
| NAME |
DATABASE_ROLE |
SWITCHOVER_STATUS |
DB_UNIQUE_NAME |
CDB |
CON_ID |
| CDBORCL |
PRIMARY |
TO STANDBY |
cdborcl |
YES |
0 |
On Standby
SQL> select NAME, DATABASE_ROLE, SWITCHOVER_STATUS,DB_UNIQUE_NAME,CDB,CON_ID from v$database;
| NAME |
DATABASE_ROLE
|
SWITCHOVER_STATUS |
DB_UNIQUE_NAME |
CDB |
CON_ID |
| CDBORCL |
PHYSICAL STANDBY |
NOT ALLOWED |
cdborcdr |
YES |
0 |
17. Confirm that the primary database protection mode
SQL> SELECT PROTECTION_MODE FROM V$DATABASE;
PROTECTION_MODE
——————————-
MAXIMUM PERFORMANCE
——————> At this point Physical standby creation completed ! Congrats.
Test SCENARIOS
=============
You can do several test scenarios to make sure changes are getting shipped to standby location.
- · Test 1 – Create Table on any PDB schema can verify the changes take effect on Standby site.
Primary
Create a table, insert some values
Standby
1. alter pluggable database all open read only;
2. Connect to PDB .
3. Select count (*) from schema.tablename
- · Test 2 – Clone a PDB and verify the changes take effect on Standby site.
Primary
CREATE PLUGGABLE DATABASE pdb2 ADMIN USER pdb2adm IDENTIFIED BY meadmin;
SQL> select name, open_mode from v$pdbs; or show pdbs;
Standby
1. Verify Alert log
2. SQL> select name, open_mode from v$pdbs; or show pdbs;
- In this exercise we are bringing up standby database on PRASSBY i.e. on HOST LABSBY1.
- LISTENER 12c – This is a static Listener to build standby database and used 1525 port.
- PRASSBY_DR – Connect String to Connect DG Instance for Standby Build and Log Shipping
- PRASPRD – Connect String to Connect Primary Instance for Standby Build and Log Shipping