A physical standby database is an exact, block-for-block copy of a primary database. A physical standby is maintained as an exact copy through a process called Redo Apply, in which redo data received from a primary database is continuously applied to a physical standby database using the database recovery mechanisms.This also means that rowids stay the same in a physical standby database environment.
A physical standby database can be opened for read-only access and used to offload queries from a primary database. If a license for the Oracle Active Data Guard option has been purchased, Redo Apply can be active while the physical standby database is open, thus allowing queries to return results that are identical to what would be returned from the primary database. This capability is known as the real-time query feature.
How Physical Standby works
On the Primary database site
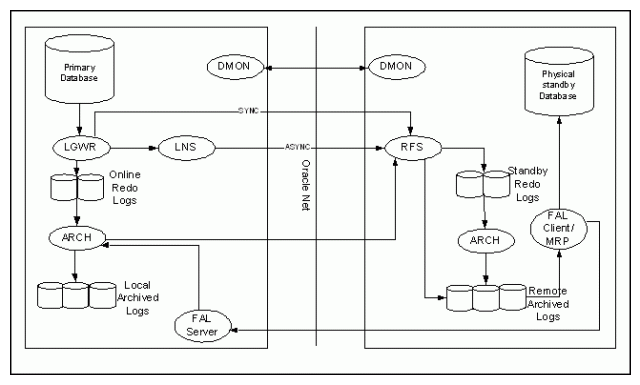
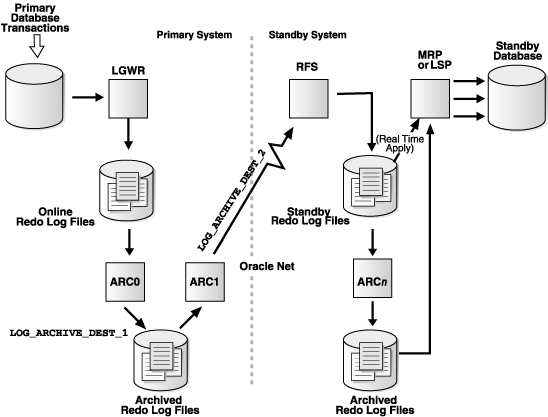
The log writer process (LGWR) collects transactions from the log buffer and writes to the online redo logs.
The archiver process (ARCH) creates a copy of the online redo logs, and writes to the local archive destination.
Depending on the configuration, the archiver process or log writer process can also transmit redo logs to standby database. When using the log writer process, you can specify synchronous or asynchronous network transmission of redo logs to remote destinations.
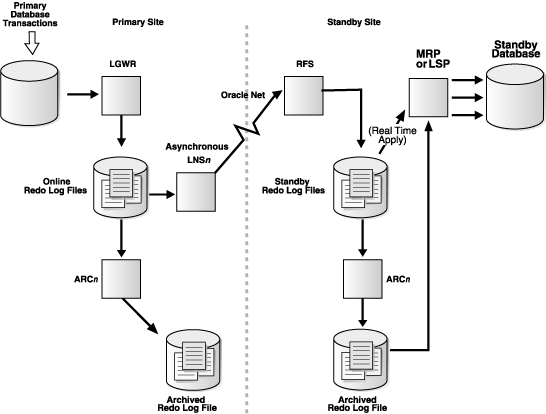
Data Guard achieves asynchronous network I/O using LGWR network server process (LNS). These network severs processes are deployed by LOG_ARCHIVE_DEST_n initialization parameter.
Data Guard’s asynchronous log transport (i.e. the Maximum Performance mode) is recommended for a configuration in which the network distance is up to thousands of miles, providing continual maximum performance, while minimizing the risks of transaction loss in the event of a disaster.
On the Standby database site
The remote file server process (RFS) receives archived redo logs from the primary database. The primary site launches the RFS process during the first log transfer.
The redo logs information received by the RFS process can be stored as either standby redo logs or archived redo logs. Data Guard introduces the concept of standby redo logs (separate pool of log file groups).
Standby redo logs must be archived by the ARCH process to the standby archived destination before the managed recovery process (MRP) applies redo log information to the standby database.
The fetch archive log (FAL) client is the MRP process. The fetch archive log (FAL) server is a foreground process that runs on the primary database and services the fetch archive log requests coming from the FAL client. A separate FAL server is created for each incoming FAL client. FAL_SERVER specifies the FAL (fetch archive log) server for a standby database. The value is an Oracle Net service name, which is assumed to be configured properly on the standby database system to point to the desired FAL server.FAL_CLIENT specifies the FAL (fetch archive log) client name that is used by the FAL service, configured through the FAL_SERVER parameter, to refer to the FAL client. The value is an Oracle Net service name, which is assumed to be configured properly on the FAL server system to point to the FAL client (standby database). Thanks to the FAL_CLIENT and FAL_SERVER parameters, the managed-recovery process in the physical database will automatically check and resolve gaps at the time redo is applied. This helps in the sense that you don’t need to perform the transfer of those gaps by yourself. FAL_CLIENT and FAL_SERVER only need to be defined in the initialization parameter file for the standby database(s). It is possible; however, to define these two parameters in the initialization parameter for the primary database server to ease the amount of work that would need to be performed if the primary database were required to transition its role.
Prior to Oracle 11g, Redo Apply only worked with the standby database in the MOUNT state, preventing queries against the physical standby whilst media recovery was in progress. This has changed in Oracle 11g.When using Data Guard Broker (DG_BROKER_START = TRUE), the monitor agent process named Data Guard Broker Monitor (DMON) is running on every site (primary and standby) and maintain a two-way communication.
Protection Mode
Maximum Protection
This mode offers the highest level of data protection. Data is synchronously transmitted to the standby database from the primary database and transactions are not committed on the primary database unless the redo data is available on at least one standby database configured in this mode. If the last standby database configured in this mode becomes unavailable, processing stops on the primary database. This mode ensures no-data-loss.
Because this data protection mode prioritizes data protection over primary database availability, Oracle recommends that a minimum of two standby databases be used to protect a primary database that runs in maximum protection mode to prevent a single standby database failure from causing the primary database to shut down.
Maximum Availability
This protection mode provides the highest level of data protection that is possible without compromising the availability of a primary database. Under normal operations, transactions do not commit until all redo data needed to recover those transactions has been written to the online redo log AND based on user configuration, one of the following is true:
- redo has been received at the standby, I/O to the standby redo log has been initiated, and acknowledgement sent back to primary
- redo has been received and written to standby redo log at the standby and acknowledgement sent back to primary
If the primary does not receive acknowledgement from at least one synchronized standby, then it operates as if it were in maximum performance mode to preserve primary database availability until it is again able to write its redo stream to a synchronized standby database.
If the primary database fails, then this mode ensures no data loss will occur provided there is at least one synchronized standby in the Oracle Data Guard configuration.
Transactions on the primary are considered protected as soon as Oracle Data Guard has written the redo data to persistent storage in a standby redo log file. Once that is done, acknowledgment is quickly made back to the primary database so that it can proceed to the next transaction. This minimizes the impact of synchronous transport on primary database throughput and response time. To fully benefit from complete Oracle Data Guard validation at the standby database, be sure to operate in real-time apply mode so that redo changes are applied to the standby database as fast as they are received. Oracle Data Guard signals any corruptions that are detected so that immediate corrective action can be taken.
Maximum Performance
This mode offers slightly less data protection on the primary database, but higher performance than maximum availability mode. In this mode, as the primary database processes transactions, redo data is asynchronously shipped to the standby database. The commit operation of the primary database does not wait for the standby database to acknowledge receipt of redo data before completing write operations on the primary database. If any standby destination becomes unavailable, processing continues on the primary database and there is little effect on primary database performance. This is the default mode.
Performance Versus Protection in Maximum Availability Mode
When you use Maximum Availability mode, it is important to understand the possible results of using the LOG_ARCHIVE_DEST_n attributes SYNC/AFFIRM versus SYNC/NOAFFIRM(FastSync) so that you can make the choice best suited to your needs.
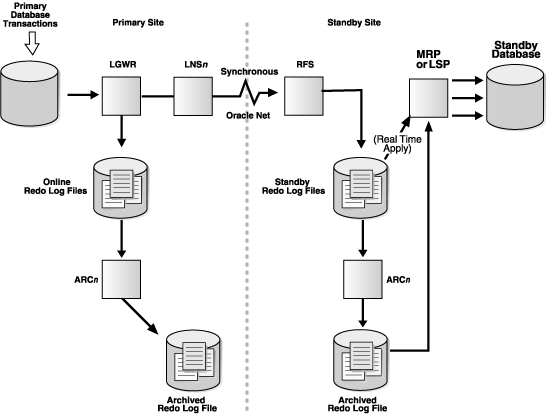
When a transport is performed using SYNC/AFFIRM, the primary performs write operations and waits for acknowledgment that the redo has been transmitted synchronously to the physical standby and written to disk. A SYNC/AFFIRM transport provides an additional protection benefit at the expense of a performance impact caused by the time required to complete the I/O to the standby redo log.
When a transport is performed using SYNC/NOAFFIRM, the primary performs write operations and waits only for acknowledgement that the data has been received on the standby,not that it has been written to disk. The SYNC/NOAFFIRM transport can provide a performance benefit at the expense of potential exposure to data loss in a special case of multiple simultaneous failures.
With those definitions in mind, suppose you experience a catastrophic failure at the primary site at the same time that power is lost at the standby site. Whether data is lost depends on the transport mode being used. In the case of SYNC/AFFIRM, in which there is a check to confirm that data is written to disk on the standby, there would be no data loss because the data would be available on the standby when the system was recovered. In the case of SYNC/NOAFFIRM, in which there is no check that data has been written to disk on the standby, there may be some data loss.
Archiving to Local Destinations Before Archiving to Remote Destinations
LGWR SYNC Archival to a Remote Destination with Standby Redo Log Files
LGWR ASYNC Archival with Network Server (LNSn) Processes
Acronyms
| Acronym | Short For |
| ARC0 | Archiver Process on Local Server |
| ARCH | Archiver |
| ASYNC | Asynchronous |
| DMON | Data Guard Monitor |
| DR | Disaster Recovery |
| FAL | Fetch Archive Log |
| LCR | Logical Change Record |
| LGWR | Logwriter |
| LNS | Network Server Process |
| LSP | Logical Standby Process (SQL Apply for Logical DG) |
| MRP | Managed Recovery Process (Redo Apply for Physical DG) |
| RFS | Remote File Server |
| SYNC | Synchronous |
| TAF | Transparent Application Failover |
